# CommonJS 和 ES6 Module 究竟有什么区别?
文章:CommonJS 和 ES6 Module 究竟有什么区别?
作者:FESKY
链接:https://juejin.cn/post/6844904080955932680
来源:掘金
作为前端开发者,你是否也曾有过疑惑,为什么可以代码中可以直接使用 require 方法加载模块,为什么加载第三方包的时候 Node 会知道选择哪个文件作为入口,以及常被问到的,为什么 ES6 Module export 基础数据类型的时候会有【引用类型】的效果?
带着这些疑问和好奇,希望阅读这篇文章能解答你的疑惑。
# CommonJS 规范
在 ES6 之前,ECMAScript 并没有提供代码组织的方式,那时候通常是基于 IIFE 来实现“模块化”,随着 JavaScript 在前端大规模的应用,以及服务端 Javascript 的推动,原先浏览器端的模块规范不利于大规模应用。于是早期便有了 CommonJS 规范,其目标是为了定义模块,提供通用的模块组织方式。
# 模块定义和使用
在 Commonjs 中,一个文件就是一个模块。定义一个模块导出通过 exports 或者 module.exports 挂载即可。
exports.count = 1;
复制代码
2
导入一个模块也很简单,通过 require 对应模块拿到 exports 对象。
const counter = require('./counter');
console.log(counter.count);
2
CommonJS 的模块主要由原生模块 module 来实现,这个类上的一些属性对我们理解模块机制有很大帮助。
Module {
id: '.', // 如果是 mainModule id 固定为 '.',如果不是则为模块绝对路径
exports: {}, // 模块最终 exports
filename: '/absolute/path/to/entry.js', // 当前模块的绝对路径
loaded: false, // 模块是否已加载完毕
children: [], // 被该模块引用的模块
parent: '', // 第一个引用该模块的模块
paths: [ // 模块的搜索路径
'/absolute/path/to/node_modules',
'/absolute/path/node_modules',
'/absolute/node_modules',
'/node_modules'
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# require 从哪里来?
在编写 CommonJS 模块的时候,我们会使用 require 来加载模块,使用 exports 来做模块输出,还有 module,__filename, __dirname 这些变量,为什么它们不需要引入就能使用?
原因是 Node 在解析 JS 模块时,会先按文本读取内容,然后将模块内容进行包裹,在外层裹了一个 function,传入变量。再通过 vm.runInThisContext 将字符串转成 Function形成作用域,避免全局污染。
let wrap = function(script) {
return Module.wrapper[0] + script + Module.wrapper[1];
};
const wrapper = [
'(function (exports, require, module, __filename, __dirname) { ',
'\n});'
];
2
3
4
5
6
7
8
于是在 CommmonJS 的模块中可以不需要 require,直接访问到这些方法,变量。
参数中的 module 是当前模块的的 module 实例(尽管这个时候模块代码还没编译执行),exports 是 module.exports 的别名,最终被 require 的时候是输出 module.exports 的值。require 最终调用的也是 Module._load 方法。__filename,__dirname 则分别是当前模块在系统中的绝对路径和当前文件夹路径。
# 模块的查找过程
开发者在使用 require 时非常简单,但实际上为了兼顾各种写法,不同类型的模块,node_modules packages 等模块的查找过程稍微有点麻烦。
首先,在创建模块对象时,会有 paths 属性,其值是由当前文件路径计算得到的,从当前目录一直到系统根目录的 node_modules。可以在模块中打印 module.paths 看看。
[
'/Users/evan/Desktop/demo/node_modules',
'/Users/evan/Desktop/node_modules',
'/Users/evan/node_modules',
'/Users/node_modules',
'/node_modules'
]
2
3
4
5
6
7
除此之外,还会查找全局路径(如果存在的话)
[
execPath/../../lib/node_modules, // 当前 node 执行文件相对路径下的 lib/node_modules
NODE_PATH, // 全局变量 NODE_PATH
HOME/.node_modules, // HOME 目录下的 .node_module
HOME/.node_libraries' // HOME 目录下的 .node-libraries
]
2
3
4
5
6
按照官方文档给出的查找过程已经足够详细,这里只给出大概流程。
从 Y 路径运行 require(X)
1. 如果 X 是内置模块(比如 require('http'))
a. 返回该模块。
b. 不再继续执行。
2. 如果 X 是以 '/' 开头、
a. 设置 Y 为 '/'
3. 如果 X 是以 './' 或 '/' 或 '../' 开头
a. 依次尝试加载文件,如果找到则不再执行
- (Y + X)
- (Y + X).js
- (Y + X).json
- (Y + X).node
b. 依次尝试加载目录,如果找到则不再执行
- (Y + X + package.json 中的 main 字段).js
- (Y + X + package.json 中的 main 字段).json
- (Y + X + package.json 中的 main 字段).node
c. 抛出 "not found"
4. 遍历 module paths 查找,如果找到则不再执行
5. 抛出 "not found"
复制代码
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
模块查找过程会将软链替换为系统中的真实路径,例如 lib/foo/node_moduels/bar 软链到 lib/bar,bar 包中又 require('quux'),最终运行 foo module 时,require('quux') 的查找路径是 lib/bar/node_moduels/quux 而不是 lib/foo/node_moduels/quux。
# 模块加载相关
# MainModule
当运行 node index.js 时,Node 调用 Module 类上的静态方法 _load(process.argv[1]) 加载这个模块,并标记为主模块,赋值给 process.mainModule 和 require.main,可以通过这两个字段判断当前模块是主模块还是被 require 进来的。
CommonJS 规范是在代码运行时同步阻塞性地加载模块,在执行代码过程中遇到 require(X) 时会停下来等待,直到新的模块加载完成之后再继续执行接下去的代码。
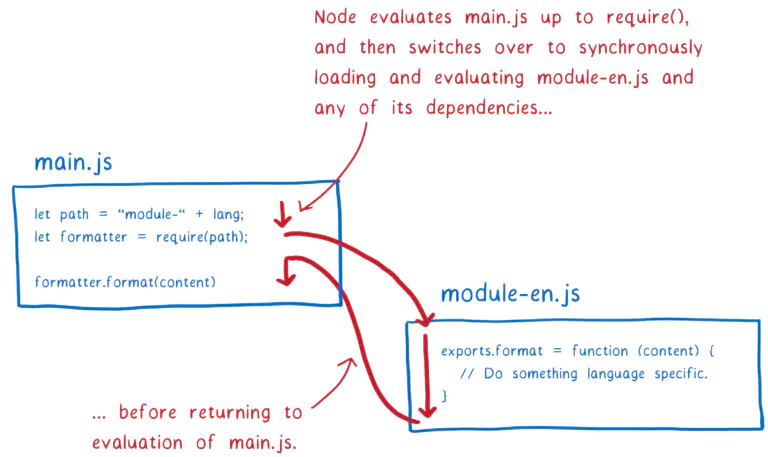
虽说是同步阻塞性,但这一步实际上非常快,和浏览器上阻塞性下载、解析、执行 js 文件不是一个级别,硬盘上读文件比网络请求快得多。
# 缓存和循环引用
文件模块查找挺耗时的,如果每次 require 都需要重新遍历文件夹查找,性能会比较差;还有在实际开发中,模块可能包含副作用代码,例如在模块顶层执行 addEventListener ,如果 require 过程中被重复执行多次可能会出现问题。
CommonJS 中的缓存可以解决重复查找和重复执行的问题。模块加载过程中会以模块绝对路径为 key, module 对象为 value 写入 cache。在读取模块的时候会优先判断是否已在缓存中,如果在,直接返回 module.exports;如果不在,则会进入模块查找的流程,找到模块之后再写入 cache。
// a.js
module.exports = {
foo: 1,
};
// main.js
const a1 = require('./a.js');
a1.foo = 2;
const a2 = require('./a.js');
console.log(a2.foo); // 2
console.log(a1 === a2); // true
2
3
4
5
6
7
8
9
10
11
12
13
以上例子中,require a.js 并修改其中的 foo 属性,接着再次 require a.js 可以看到两次 require 结果是一样的。
模块缓存可以打印 require.cache 进行查看。
{
'/Users/evan/Desktop/demo/main.js':
Module {
id: '.',
exports: {},
parent: null,
filename: '/Users/evan/Desktop/demo/main.js',
loaded: false,
children: [ [Object] ],
paths:
[ '/Users/evan/Desktop/demo/node_modules',
'/Users/evan/Desktop/node_modules',
'/Users/evan/node_modules',
'/Users/node_modules',
'/node_modules'
]
},
'/Users/evan/Desktop/demo/a.js':
Module {
id: '/Users/evan/Desktop/demo/a.js',
exports: { foo: 1 },
parent:
Module {
id: '.',
exports: {},
parent: null,
filename: '/Users/evan/Desktop/demo/main.js',
loaded: false,
children: [Array],
paths: [Array] },
filename: '/Users/evan/Desktop/demo/a.js',
loaded: true,
children: [],
paths:
[ '/Users/evan/Desktop/demo/node_modules',
'/Users/evan/Desktop/node_modules',
'/Users/evan/node_modules',
'/Users/node_modules',
'/node_modules' ] } }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
缓存还解决了循环引用的问题。举个例子,现在有模块 a require 模块 b;而模块 b 又 require 了模块 a。
// main.js
const a = require('./a');
console.log('in main, a.a1 = %j, a.a2 = %j', a.a1, a.a2);
// a.js
exports.a1 = true;
const b = require('./b.js');
console.log('in a, b.done = %j', b.done);
exports.a2 = true;
// b.js
const a = require('./a.js');
console.log('in b, a.a1 = %j, a.a2 = %j', a.a1, a.a2);
2
3
4
5
6
7
8
9
10
11
12
13
程序执行结果如下:
in b, a.a1 = true, a.a2 = undefined
in main, a.a1 = true, a.a2 = true
2
实际上在模块 a 代码执行之前就已经创建了 Module 实例写入了缓存,此时代码还没执行,exports 是个空对象。
'/Users/evan/Desktop/module/a.js':
Module {
exports: {},
//...
}
}
2
3
4
5
6
代码 exports.a1 = true; 修改了 module.exports 上的 a1 为 true, 这时候 a2 代码还没执行。
'/Users/evan/Desktop/module/a.js':
Module {
exports: {
a1: true
}
//...
}
}
2
3
4
5
6
7
8
进入 b 模块,require a.js 时发现缓存上已经存在了,获取 a 模块上的 exports 。打印 a1, a2 分别是 true,和 undefined。
运行完 b 模块,继续执行 a 模块剩余的代码,exports.a2 = true; 又往 exports 对象上增加了 a2 属性,此时 module a 的 export 对象 a1, a2 均为 true。
exports: {
a1: true,
a2: true
}
2
3
4
再回到 main 模块,由于 require('./a.js') 得到的是 module a export 对象的引用,这时候打印 a1, a2 就都为 true。
小结:
CommonJS 模块加载过程是同步阻塞性地加载,在模块代码被运行前就已经写入了 cache,同一个模块被多次 require 时只会执行一次,重复的 require 得到的是相同的 exports 引用。
值得留意: cache key 使用的是模块在系统中的绝对位置,由于模块调用位置的不同,相同的 require('foo') 代码并不能保证返回的是统一个对象引用。我之前恰巧就遇到过,两次 require('egg-core') 但是他们并不相等。
# ES6 模块
ES6 模块是前端开发同学更为熟悉的方式,使用 import, export 关键字来进行模块输入输出。ES6 不再是使用闭包和函数封装的方式进行模块化,而是从语法层面提供了模块化的功能。
ES6 模块中不存在 require, module.exports, __filename 等变量,CommonJS 中也不能使用 import。两种规范是不兼容的,一般来说平日里写的 ES6 模块代码最终都会经由 Babel, Typescript 等工具处理成 CommonJS 代码。
使用 Node 原生 ES6 模块需要将 js 文件后缀改成 mjs,或者 package.json "type" 字段改为 "module",通过这种形式告知 Node 使用 ES Module 的形式加载模块。
# ES6 模块 加载过程
ES6 模块的加载过程分为三步:
# 1. 查找,下载,解析,构建所有模块实例。
ES6 模块会在程序开始前先根据模块关系查找到所有模块,生成一个无环关系图,并将所有模块实例都创建好,这种方式天然地避免了循环引用的问题,当然也有模块加载缓存,重复 import 同一个模块,只会执行一次代码。
# 2. 在内存中腾出空间给即将 export 的内容(此时尚未写入 export value)。然后使 import 和 export 指向内存中的这些空间,这个过程也叫连接。
这一步完成的工作是 living binding import export,借助下面的例子来帮助理解。
// counter.js
let count = 1;
function increment () {
count++;
}
module.exports = {
count,
increment
}
// main.js
const counter = require('counter.cjs');
counter.increment();
console.log(counter.count); // 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
上面 CommonJS 的例子执行结果很好理解,修改 count++ 修改的是模块内的基础数据类型变量,不会改变 exports.count,所以打印结果认为 1。
// counter.mjs
export let count = 1;
export function increment () {
count++;
}
// main.mjs
import { increment, count } from './counter.mjs'
increment();
console.log(count); // 2
2
3
4
5
6
7
8
9
10
11
12
从结果上看使用 ES6 模块的写法,当 export 的变量被修改时,会影响 import 的结果。这个功能的实现就是 living binding,具体规范底层如何实现可以暂时不管,但是知道 living binding 比网上文章描述为 "ES6 模块输出的是值的引用" 更好理解。
更接近 ES6 模块的 CommonJS 代码可以是下面这样:
exports.counter = 1;
exports.increment = function () {
exports.counter++;
}
2
3
4
5
# 3. 运行模块代码将变量的实际值填写在第二步生成的空间中。
到第三步,会基于第一步生成的无环图进行深度优先后遍历填值,如果这个过程中访问了尚未初始化完成的空间,会抛出异常。
// a.mjs
export const a1 = true;
import * as b from './b.mjs';
export const a2 = true;
// b.mjs
import { a1, a2 } from './a.mjs'
console.log(a1, a2);
2
3
4
5
6
7
8
上面的例子会在运行时抛出异常 ReferenceError: Cannot access 'a1' before initialization。如果改成 import * as a from 'a.mjs' 可以看到 a 模块中 export 的对象已经占好坑了。
// b.mjs
import * as a from './a.mjs'
console.log(a);
2
3
将输出 { a1: <uninitialized>, a2: <uninitialized> } 可以看出,ES6 模块为 export 的变量预留了空间,不过尚未赋值。这里和 CommonJS 不一样,CommonJS 到这里是知道 a1 为 true, a2 为 undefined
除此之外,我们还能推导出一些 ES6 模块和 CommonJS 的差异点:
CommonJS可以在运行时使用变量进行 require, 例如require(path.join('xxxx', 'xxx.js')),而静态import语法(还有动态 import,返回Promise)不行,因为 ES6 模块会先解析所有模块再执行代码。

require会将完整的exports对象引入,import可以只import部分必要的内容,这也是为什么使用Tree Shaking时必须使用 ES6 模块 的写法。import另一个模块没有export的变量,在代码执行前就会报错,而CommonJS是在模块运行时才报错。
# 为什么平时开发可以混写?
前面提到 ES6 模块和 CommonJS 模块有很大差异,不能直接混着写。这和开发中表现是不一样的,原因是开发中写的 ES6 模块最终都会被打包工具处理成 CommonJS 模块,以便兼容更多环境,同时也能和当前社区普通的 CommonJS 模块融合。
在转换的过程中会产生一些困惑,比如说:
# __esModule 是什么?干嘛用的?
使用转换工具处理 ES6 模块的时候,常看到打包之后出现 __esModule 属性,字面意思就是将其标记为 ES6 Module。这个变量存在的作用是为了方便在引用模块的时候加以处理。
例如 ES6 模块中的 export default 在转化成 CommonJS 时会被挂载到 exports['default'] 上,当运行 require('./a.js') 时 是不能直接读取到 default 上的值的,为了和 ES6 中 import a from './a.js' 的行为一致,会基于 __esModule 判断处理。
// a.js
export default 1;
// main.js
import a from './a';
console.log(a);
2
3
4
5
6
7
转化后
// a.js
Object.defineProperty(exports, "__esModule", {
value: true
});
exports.default = 1;
// main.js
'use strict';
var _a = require('./a');
var _a2 = _interopRequireDefault(_a);
function _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }
console.log(_a2.default);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
a 模块 export defualt 会被转换成 exports.default = 1;,这也是平时前端项目开发中使用 require 为什么还常常需要 .default 才能取到目标值的原因。
接着当运行 import a from './a.js' 时,es module 预期的是返回 export 的内容。工具会将代码转换为 _interopRequireDefault 包裹,在里面判断是否为 esModule,是的话直接返回,如果是 commonjs 模块的话则包裹一层 {default: obj},最后获取 a 的值时,也会被装换成 _a1.default。