# node-crawler爬虫
项目中issue添加新的题目,手动修改和添加项目分类的统计数据比较繁琐,考虑使用nodejs抓取issue页面数据, 源码位置
# 爬虫简介
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
# 开发流程
- 确定爬取对象(网站/页面)
- 分析页面内容(目标数据/DOM结构)
- 确定开发语言、框架、工具等
- 编码 测试,爬取数据
- 优化
# 核心代码
# 页面抓取与dom生成
cheerio
const request = require('request')
const cheerio = require('cheerio')
request('https://www.baidu.com', function (error, response, body) {
if (!error && response.statusCode == 200) {
// console.log(body) // 打印百度首页
const $ = cheerio.load(body) // nodejs cheerio模块 模拟jqeury核心功能
const nodeElement = $('input') // 查询百度首页所有input元素
} else {
console.log(error)
}
})
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
# 动态生成md文件
使用fs和os,清空文件,动态逐行写入文件
var fs = require('fs')
var os = require('os')
fs.writeFile('./test.md', '', function () {
var fWriteName = file;
// 逐行写入流
var fWrite = fs.createWriteStream(fWriteName);
const list = []
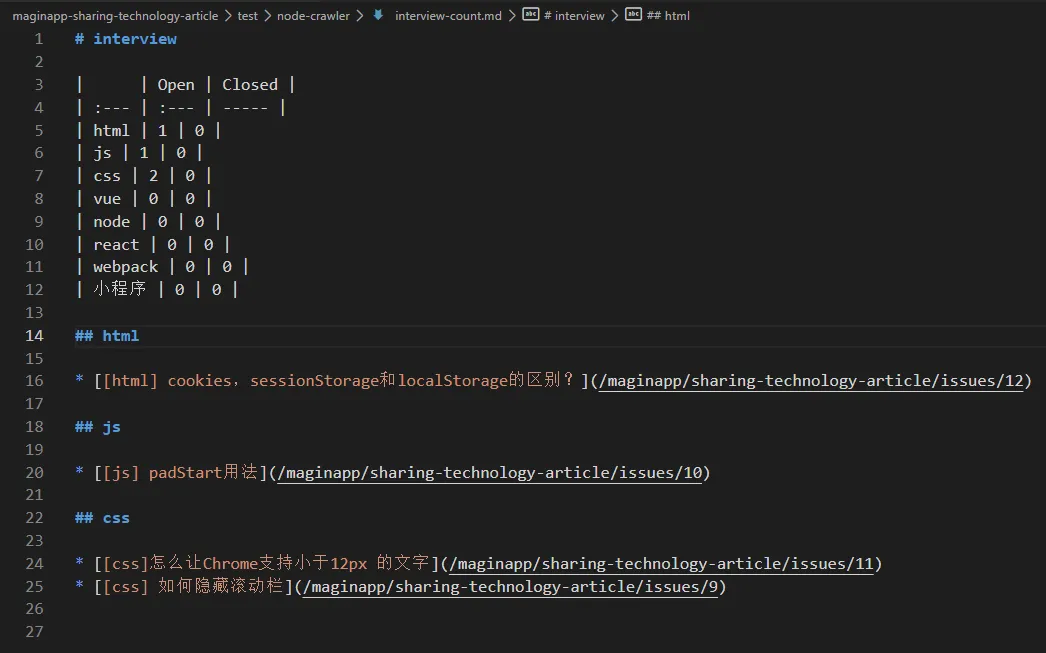
list.push('# interview')
list.push('')
list.push('| | Open | Closed |')
list.push('| :--- | :--- | ----- |')
// 写入文件
fWrite.write(item + os.EOL)
})
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
# 使用中出现的问题
github页面抓取时,经常出现node请求报错,使用curl模拟请求也出现了此问题:
Node.js request module getting ETIMEDOUT and ESOCKETTIMEDOUT
ETIMEDOUT 192.30.255.113:443
at TCPConnectWrap.afterConnect [as oncomplete] (net.js:1146:16) {
errno: -4039,
code: 'ETIMEDOUT',
syscall: 'connect',
address: '192.30.255.113',
port: 443
}
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
解决方法:
- 请求报错时,重新发起请求
- 配置请求参数,延长超时时间,增加socket pool数量
{
// ...
timeout: 1000 * 60,
pool: {
maxSockets: Infinity
}
// ...
}
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
- 降低请求频率,添加抓取页面请求延时
- 随机生成
ua和ip
# 其他思路
使用 github api 获取issue相关数据,暂未找到统计数据